基本信息
- 论文: Answering Questions about Charts and Generating Visual Explanations
- 作者: Dae Hyun Kim, Enamul Hoque, Maneesh Agrawala
- 来源: CHI 2020
动机
利用可视化来分析数据、回答问题和解释如何获得该答案是不少决策任务的核心。
但基于可视化的分析任务并不总是那么简单:常常需要组合一些不同操作才能获得最终的答案,如下图所示
能否将上述过程自动化?
- 自动化的可视化问答系统(VisQA)可以减少用户在进行各种复杂操作上的时间精力
- 在数据分析的工作流程中引入自然语言界面,可以降低用可视化图表分析数据所需的门槛;没有正规数据分析训练和可视化素养的用户也可用
自动化的难点
- 如何透明地解释该问答系统为何给出这个答案?
- 需要视觉化的解释(visual explanations):调研表明,最有效的解释是描述“答案是如何依据图表上的视觉特征得到的”
方法
前期调研
- 对图表、问题、回答、解释的调研
- 收集 47 个柱状图与 5 个折线图
- 每人用自然语言写 5 个关于上述图表的问题(Q),回答(A)10 个问题,并提供对应的解释(E)。
- 问题分类:单一数值检索 lookup /复合型 compositional (70%)
- 复合型的例子:极值;两个数值差异;多个值的和等等
- 问题和解释的分类: 视觉化 visual (51%) /非视觉化 non-visual
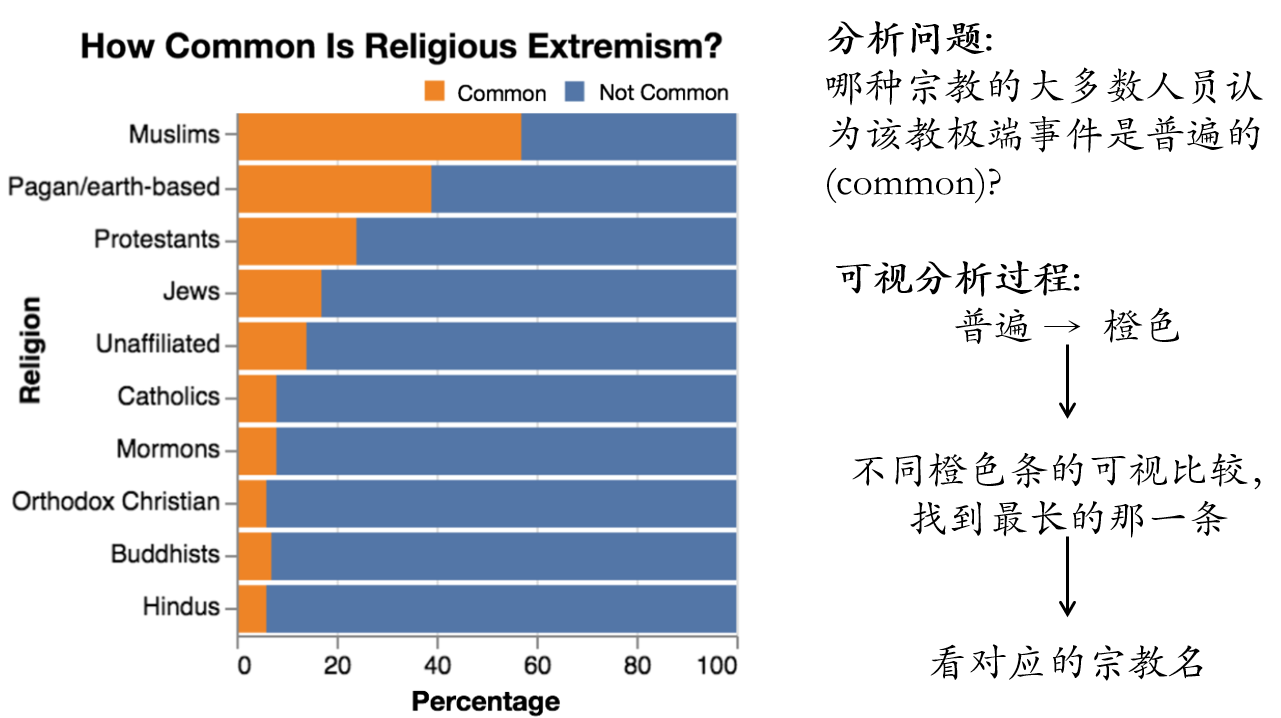
- 视觉化的例子:利用到了图表的视觉特征,比如“muslin 在柱状图中有最长的橙色条”
- 非视觉化例子:仅和数据有关,如”muslin 中有 57%认为是常见的,是比所有其他宗教都多的“
- 从学校同事那额外收集了 277 个视觉化问题以分析涉及标记、可视属性的词法、句法结构
自动化可视化问答系统流水线
三个步骤:
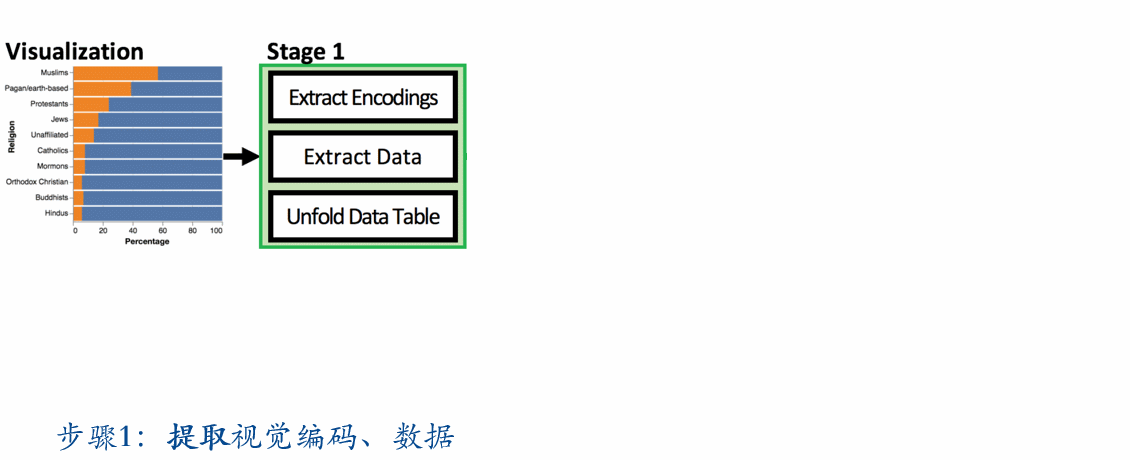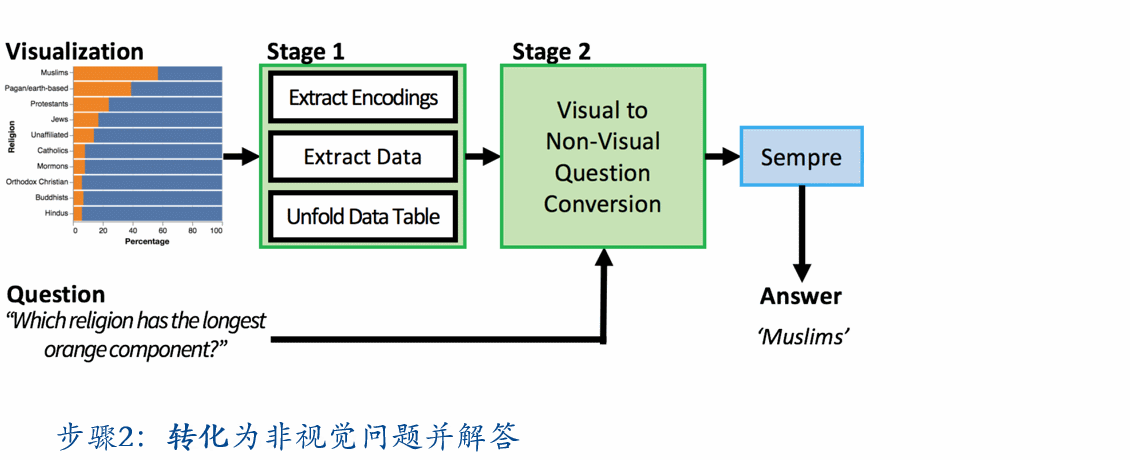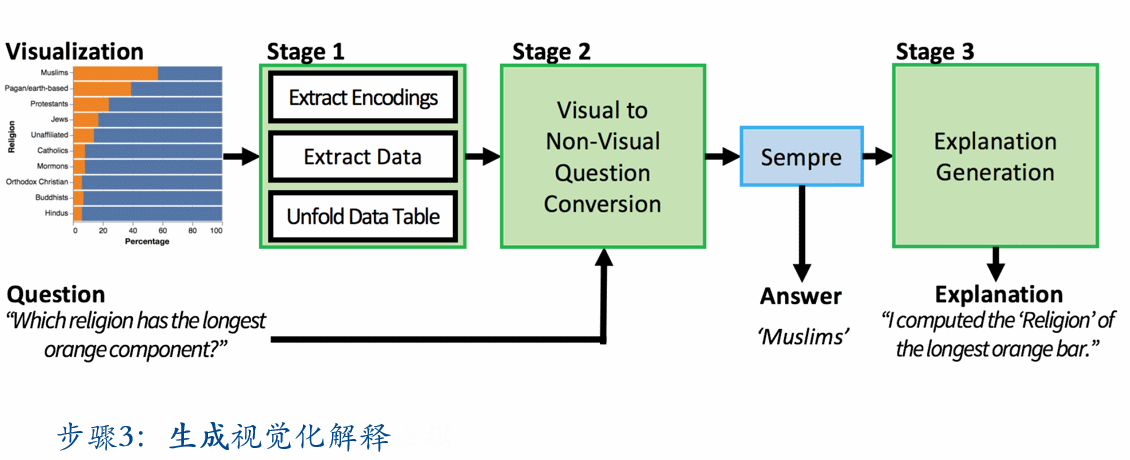
- 第一步提取可视化中的可视编码、提取数据并将数据整理成 unfolded 数据表(为了下一步的 Sempre 的使用)
- 如果可视化本身是 vega-lite,这一步可以直接从 vega-lite 的 specification 找到;如果是 D3,可以用他们以前做的 D3 deconstructor;如果是位图,可以用 ReVision(多年前由李飞飞、本文通讯作者、以及 Jeffrey Heer 合作的对可视化进行解析的工作)

- 如果可视化本身是 vega-lite,这一步可以直接从 vega-lite 的 specification 找到;如果是 D3,可以用他们以前做的 D3 deconstructor;如果是位图,可以用 ReVision(多年前由李飞飞、本文通讯作者、以及 Jeffrey Heer 合作的对可视化进行解析的工作)
第二步转换为非视觉问题,主要思想就是把视觉问题里的视觉元素一步步替换为数据集本身的元素。

第三步生成视觉化解释:结合 Sempre 在回答问题时产生的 λ 表达式与自然语言模板生成

总的来说,其实是一种自然语言到自然语言的变换,过程中做了两次翻译,利用了 Sempre 这个工具作出了回答。
案例
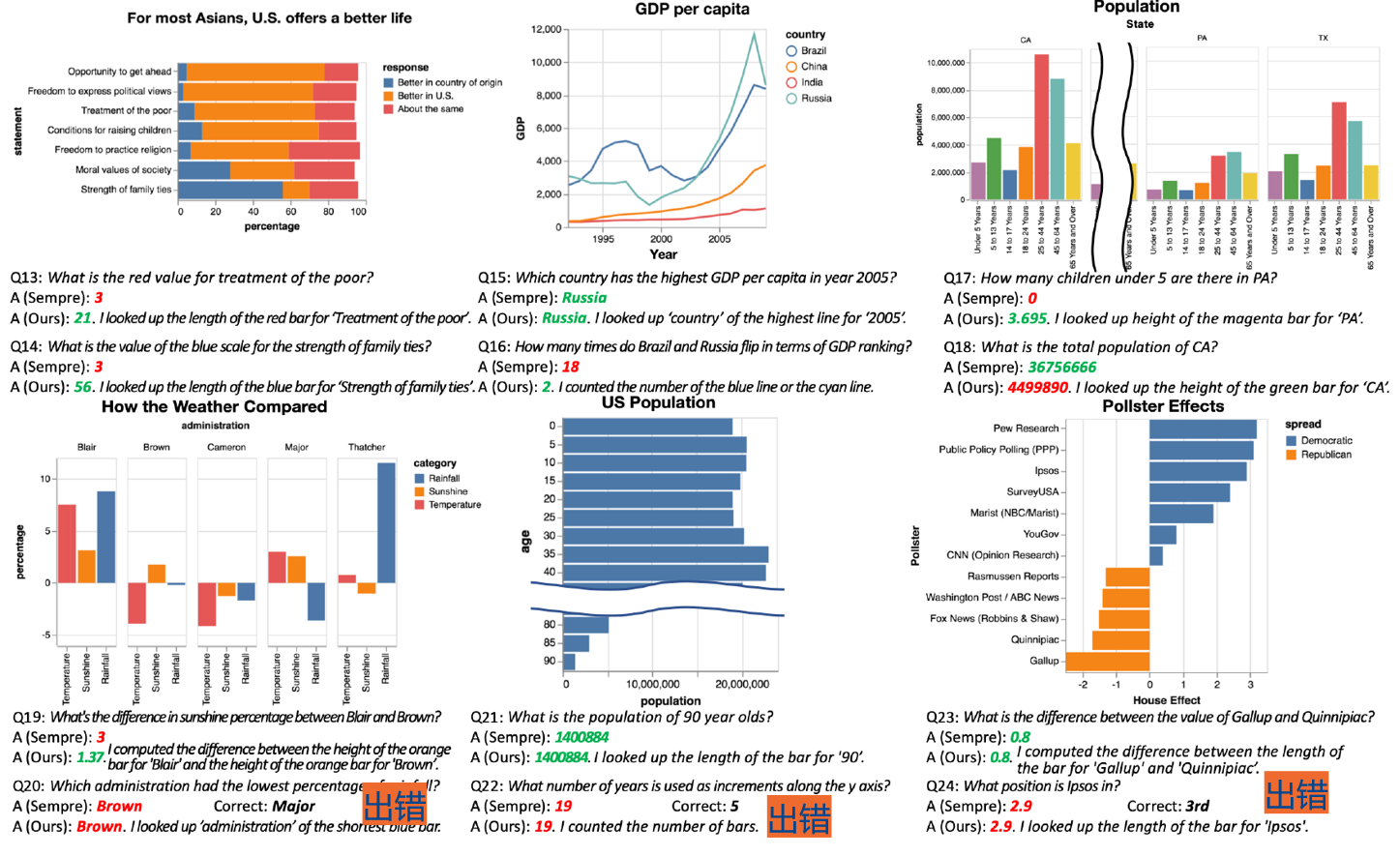
文中给出了一些案例,可以看到最后几个回答也出现了错误。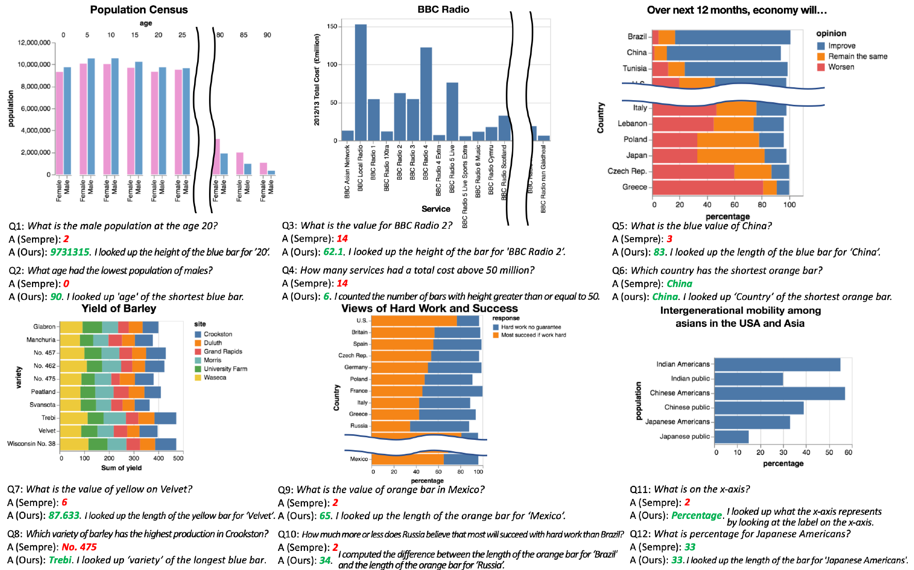
评估
方法性能
与仅用 Sempre 比较准确性,各方面完胜。但是注意到,总体准确率也仅有 51%。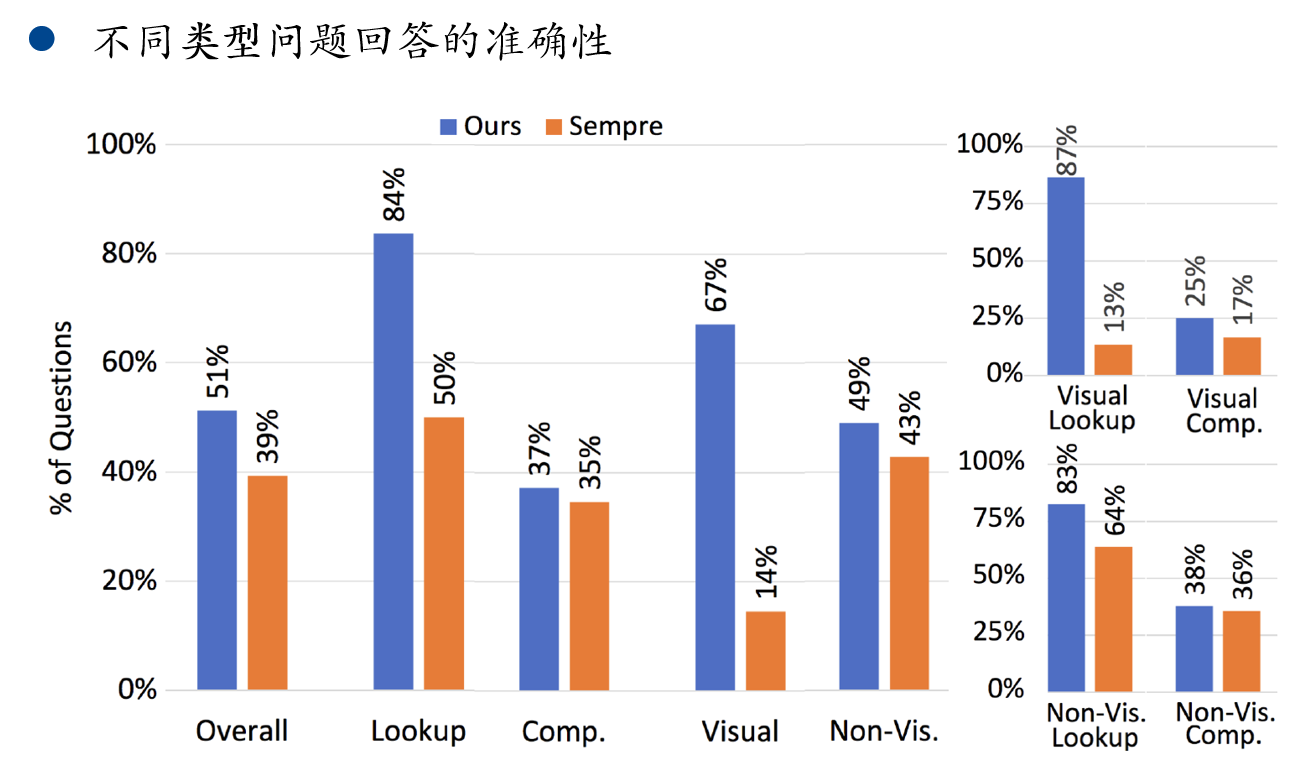
各个步骤的必要性。
用户调研
16 人,within-subject。
视觉化的解释相比没有解释显著提升了透明度;信任度有提升但不显著
视觉化的解释比人写的解释显著提升了透明度;信任度方面提升不大
视觉化与非视觉化的解释,从透明度、信任度和有用度相比起来,都比后者高但都不显著。
不足与未来工作
- QA 中的 Q 多样性仍然不够,对应的解答也一样不够丰富。
- 解释的方式也不够丰富。其实仔细一想,本文方法仍然是基于规则的,数据仍然是基于他们收集的数据。但是提供了一个很好的可行思路。
- 可视化的多样性不足在文中并未提及
- 文中只有条形图与折线图。这两种在网上最多;先前一篇调研也表面他们其实是最容易让大众读懂的。但诸如饼图等也很简单,本文并未提到;猜测与 CHI 的文章特性有关:可操作性强、能实现出来。
相关工作与个人感言
用自然语言与可视化交互的工作
今年来由于普通用户对可视化需求越开越大,这方面的工作也越来越多,这里仅列举一部分,有兴趣的朋友可以看看原文了解最新进展。
自然语言“产生”可视化
自然语言对可视化的引用、辅助文字阅读

本身上述不少工作是有商业产品背景的,这里再列举一些商业智能 BI 或者可视化叙事 storytelling 的产品。
自然语言生成/可视化生成的商业产品/插件
Tableau。可以看到这个自然语言生成的结果也很模板划,不过这是多年前的产品截图了。
YellowFin。从广告简介来看,该公司的 assisted insight 比 automated insight 更接近我们可视分析“human in the loop”的思路,并且受众不是可视化专家而是更为普通的 BI 用户。
Calliope / 同济大学曹楠老师组。自动 insight 发现、故事生成。自动化方法,但支持各种可配置项进行定制。
对于文章背后 idea、思路的思考
一些大佬们的作品的共性
- GraphScape 用了线性规划对不同可视化之间 transition 代价建模
- Draco 用了 Answer Set Programming 对可视化设计中的软限制、硬限制建模
没有用比较高深的机器学习/深度学习方法;用的方法都比较可解释
- 大家都用了 Vega-Lite:可视化还是比较结构化的东西,很多情况下如果当做位图来处理可能还是没那么有效
- l 大多数情况还是需要人工标注、人工生成的信息
✉️ akiori@zju.edu.cn